
附件下载:
下载链接 null
安装链接 null
下载链接 null
安装链接 null
下载链接 null
使用jTessBoxEditor将多个tif文件合并成一个tif。 null
lang null
-l lang null
使用tesseract识别中文,但是tesseract自带的库会识别错误或者不识别,接下来我们训练自己的识别库进行识别
一 准备阶段
1、tesseract: 下载链接 。注意尽量还是不要下载带dev,alpha,beta等,不稳定,可能是测试版本。比如说你是64位windows系统,可以下载 tesseract-ocr-w64-setup-5.3.3.20231005.exe。 安装链接 。
安装成功后配置环境变量 (1)系统变量的path增加: C:\Program Files\Tesseract-OCR (2)新增TESSDATA_PREFIX的系统变量,变量值:C:\Program Files\Tesseract-OCR\tessdata
2、java的JDK:因为编辑训练集的工具是java开发的,运行该工具需要java环境。 下载链接 。 安装链接 。 3、jTessBoxEditor: 下载链接 。这个下载的是不需要安装的,如果你JDK安装没错的话点击train.bat文件就可以启动了。
二 训练阶段
1、打开jTessBoxEditor目录,双击train.bat运行,点击Tools中的Merge TIFF
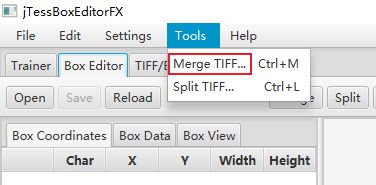
2、文件类型选择All Image Files,选择样本图片,点击打开。
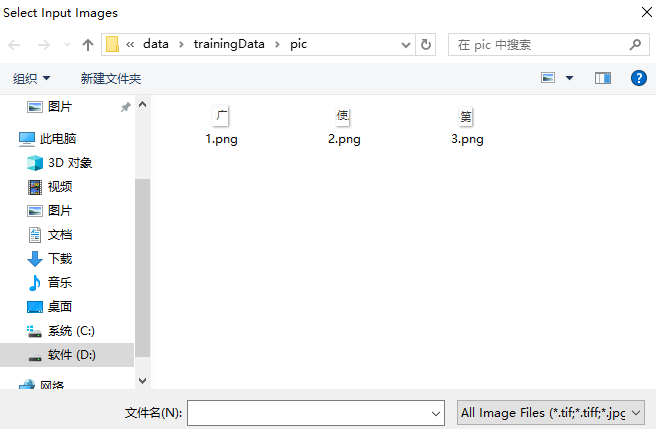
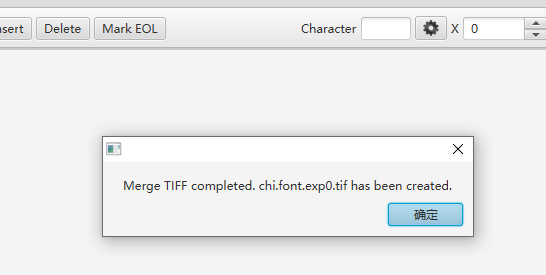
3、文件名输入chi.font.exp0.tif,文件类型选择TIFF,点击保存。
4、点击确定
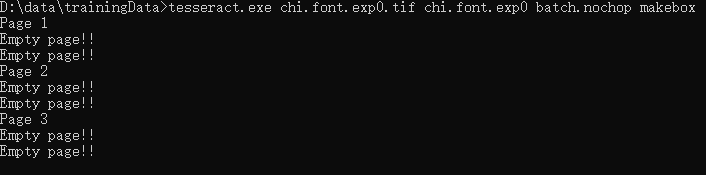
5、打开cmd进入到TIF文件所在目录,执行下面命令,生成num.font.exp0.box
【注意】以简体中文字库识别,用其他字库解析不出来。- l chi_sim代表用简体中文识别,如果安装的tesseract没有中文字体库,需自行下载放到Tesseract-OCR的tessdata目录
生成的box文件为num.font.exp0.box,box文件为Tesseract识别出的字符及其坐标。
注:Make Box File 文件名有一定的格式,不能随便乱取名字,命令格式为:
其中lang为语言名称,fontname为字体名称,num为序号,可以随便定义。
6、点击Box Editor ,点击open,选择照片num.font.exp0.tif(之前生成得的tif图片),出现下面的图片
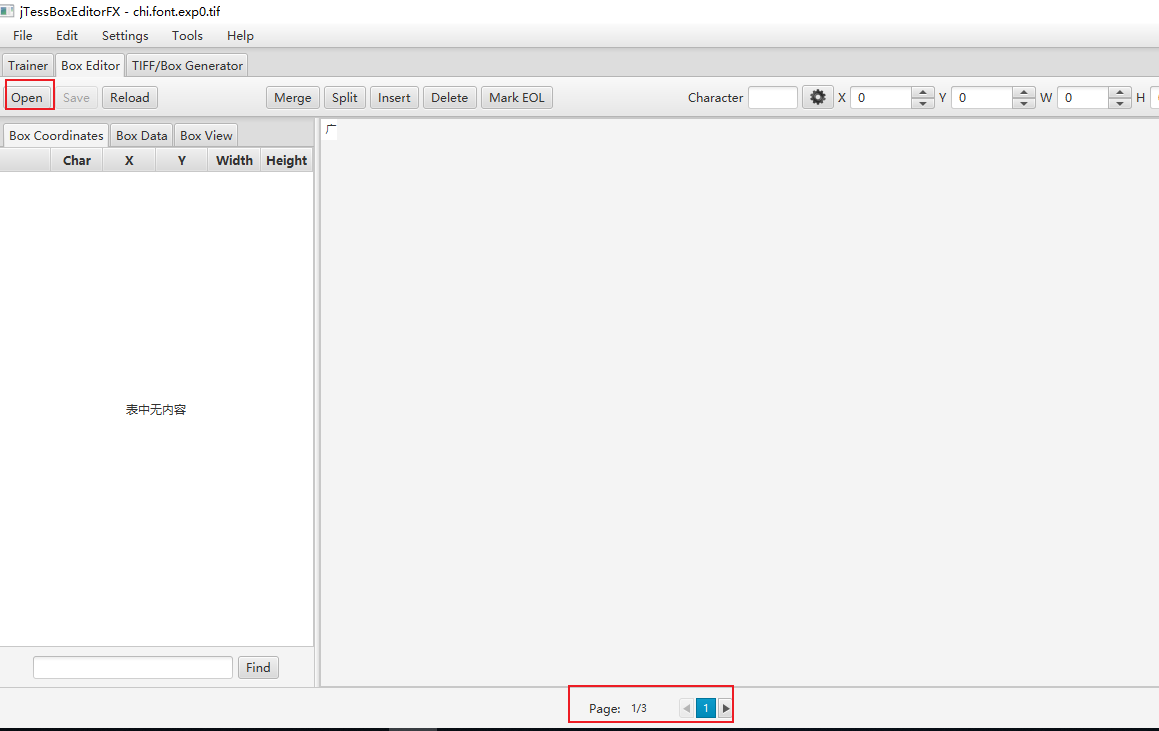
7、可以看出上面有些字符识别的位置不准确,可以通过该工具手动对每张图片中识别错误的字符和位置进行校正。校正完成后保存即可。
注: 这里必须修改识别错误的字符,否则做出来的traineddata文件也是错的。可以在下面的界面中修改并保存,也可以直接在traineddata文件中修改。
8、产生字符特征文件,生成.tr文件。命令如下:
输出结果如下:
9、计算字符集,生成一个unicharset文件。命令如下:
输出结果如下:
10、 定义字体特征文件,新建一个font_properties文件。注意,文件的名字就是font_properties,它没有.txt后缀。里面内容写入 font 0 0 0 0 0 表示默认普通字体。注意这里的font要和chi.font.exp0.tif中的font一样。
11、聚集字符特征,按顺序运行如下命令:
命令1:
输出结果如下:
命令2:
执行结果:
命令3:
输出结果如下:
运行完上面的那些命令后,会有如下五个文件:
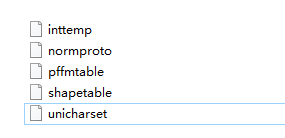
在这五个文件前加上font.(这的font.也应该和chi.font.exp0.tif中的font一样)进行重命名,最后会变成如下样子:
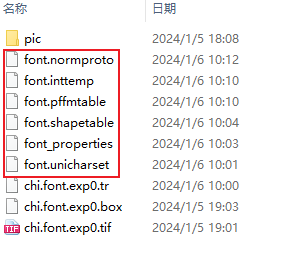
12、合并五个文件,执行如下命令,会生成目标文件font.traineddata,该文件就是训练好的字库。将它复制到你安装的Tesseract程序目录下的“tessdata”目录下即可。
输出结果如下:
注:
有时候命令行中会出现很多empty page,查阅文档,发现tesseract 是可以设置psm参数的,如下参数
于是采用了tesseract.exe chi.font.exp0.tif chi.font.exp0 --psm 7 batch.nochop makebox生成box文件,没有报错了

